Diglossia in Arabic refers to the existence of two distinct varieties: Spoken Arabic (SA), which is used orally in daily communication, and literary Arabic (LA), used in reading, writing, and for formal functions. Similarly, bilinguals often use different languages (L1, L2) for different purposes, so the question presents itself: Is Arabic diglossia a type of bilingualism? Because behavioral and fMRI studies provide contradictory answers, the current paper develops a cognitive account grounded in memory-based automaticity to align available evidence pertaining to diglossia into one developmental profile. It is theorized that Arabic native speakers use episodic memory as a mechanism to acquire both SA and LA as a first language, but, due to item-based learning, use SA and LA in a way that sometimes resembles bilinguals' use of L1 and L2. This theoretical account further guided an empirical investigation of diglossia at the level of the text. The reported study examined whether meaning-based facilitations—caused by episodic text representations and previously found to occur across thematically related texts in one language—would also occur across SA and LA thematically related texts. Consistent with the proposal, reading a text in either SA or LA was facilitated by prior reading of a thematically related text, regardless of whether the prior reading was in SA or LA. This finding is relevant in the current social context, where Arabic speakers are increasingly exposed to SA written content on social media, and where their ability to integrate the knowledge they acquire from either variety can play a critical role in increasing their reading fluency and shaping their overall reading experience.
Diglossia, Arabic, Automaticity, Episodic memory, Item-based learning, Text processing
The typical language development of native Arabic speakers entails acquiring two distinct varieties that represent differences at the phonological, morphological, syntactic, and semantic levels [1-4]. Spoken Arabic (SA) is the variety they are exposed to from birth and develop the ability to use for oral communication in everyday life. Literary Arabic (LA) is the variety they acquire through formal education and develop the ability to use in reading and writing and for formal functions [5-7]. This situation in which two distinct varieties of the same language have complementary functions in different settings is referred to as diglossia [8]. However, diglossia raises a question: Do SA and LA simply function as different varieties of the same language, or do they actually, cognitively, function as different languages? If they function as different languages, the diglossic situation could perhaps be better understood as an instance of bilingualism, in which two languages, L1 and L2, co-exist.
To determine whether SA and LA are cognitively represented as L1 and L2, investigators have drawn on research methods used in bilingualism. Patterns obtained from adult native Arabic speakers using SA and LA are compared with the patterns obtained from bilinguals while using L1 and L2. In auditory lexical-decision tasks, for example, it has been found that for Arabic bilinguals, SA primes LA and L2 targets more strongly than LA or L2 primes SA targets [9]. This asymmetrical priming pattern is the same as exhibited by bilinguals, for whom L1 primes L2 more strongly than the reverse [10,11]. Furthermore, when LA targets were preceded by L2 or SA translation equivalents, the L2 primes were more effective [12]. On the other hand, for SA targets, SA, LA, and L2 primes were initially similar. Even so, when 8-12 unrelated items intervened between primes and targets, the priming effect was weakened for LA and L2 primes, whereas SA primes were not affected [13]. In short, these experiments appear to provide support for the view that LA and SA are linked in a way similar to how L1 and L2 are linked in bilingualism; that is, in separate lexicons [14,15]. The tentative conclusion is that learners of LA are learning not a formal register of their native tongue, but, effectively, an L2 [13]. Such results would help explain why Arabic children have difficulty acquiring LA, as they must learn phonemes, syllabic structures, and words that do not exist in SA [2-4,16,17].
Regardless of the evidence for the L1 vs. L2 status of SA and LA, Boudelaa and Marslen-Wilson's [18] investigation of the cognitive operations underlying SA and LA word processing provided the first experimental evidence against this classification. Arabic words are morphologically complex as they consist of two bound morphemes: The root, which carries the general meaning, and the pattern, a phonological template into which a root can be inserted to get a specific meaning and grammatical category [19]. Earlier investigations of LA word processing found strong priming effects when primes and targets contained the same root or the same pattern [20-23]. Boudelaa and Marslen-Wilson used an auditory-auditory task and found identical root and pattern priming effects between SA words. Such results—combined with evidence that learning an L2 before puberty can lead to native-like performance [24,25] and to representing the L2 in the same cortical areas as the L1 [26] — led Boudelaa and Marslen-Wilson to argue against the previous classification of LA as an L2. It should also be noted that Arab children begin the acquisition of LA not only before puberty but even before the onset of formal education through the media they watch at home [18].
As studies of diglossia were limited to uncovering the cognitive aspects of SA and LA, a new line of studies extended the investigations to uncovering the neural processes underlying the two varieties. fMRI responses collected during semantic categorization of visually presented SA and LA words showed similar activation in the left hemisphere, with SA stimuli generating stronger activation in frontal and temporal areas due to their unfamiliarity in the visual modality. Similarly, behavioral measures showed that responses were faster and more accurate to LA than to SA stimuli. The advantage of LA in the visual modality suggests that differences between SA and LA should be viewed as modality-dependent, not L1 vs. L2-dependent [27]. Research into the neural mechanisms underlying SA and LA production has found that they activate similar brain patterns during picture naming, even though the task was easier in SA [28]. When the picture-naming task occurred in a context requiring switching between SA and LA, activation increased in the six areas known to be activated in language control processes: The left IPL, IFG, precentral gyrus, SMA, ACC and CN [29-31]. Such need for language control reflects a higher level of lexical competition between SA and LA, again suggesting that they depend on a shared lexical system, not separate systems [32].
Arabic speakers acquire SA from birth and use it in daily oral communication; they acquire LA largely through formal education and use it for written communication in formal settings. In fact, as mentioned earlier, school is not usually the first point of contact between Arab children and LA, as they are exposed to this variety at home from a very young age. Given such early exposure and complementary use of both varieties, Arabic native speakers develop a shared lexical system for their production [32] and a similar cognitive mechanism for their processing [18].
However, the foregoing developmental profile is much affected by how SA and LA are practiced. Continually using SA in oral communication improves performance on SA auditory stimuli [9,12,13], whereas continually using LA in reading and writing improves performance on LA visual stimuli [27]. Therefore, providing fast, accurate responses on SA or LA tasks does not depend on how much the variety was practiced overall, but rather on whether the task demands match the way the variety was usually practiced. Arabic speakers seem to develop an association between a specific stimulus and its response and therefore modality-dependent differences emerge. This is further reflected on the neural level. For example, processing an SA written stimulus—which is normally practiced orally—recruited stronger brain activation in left frontal and temporal areas than an LA written stimulus, normally practiced in written form [27].
Although Arabic speakers process morphologically complex SA and LA words with the same cognitive mechanisms [18], the benefits of continuous practice of SA words in oral communication seems to be restricted to this variety. The benefits do not extend to other stimuli—including LA words—even if they are processed by the same cognitive mechanism. This suggests that the learning process involves specific items rather than general processes.
The development of such a profile aligns with the instance theory of automaticity, which conceptualizes episodic memory as a learning mechanism for skilled performance. According to the theory, practice helps beginning learners develop skilled performance through encoding and retrieving specific items from memory rather than acquiring a set of rules and processes that can be generalized across items [33,34]. However, learners do not develop skilled performance by practicing a stimulus in isolation. Rather, they learn a given stimulus associated with its response. Instance theory assumes that learners perform a task using whatever algorithmic rules and processes are needed to reach a response. However, each time they practice the task, they store the associated response in long-term memory as a separate instance. This builds a knowledge base for the practiced task, and with the increased number of instances, the knowledge base becomes more reliable to the point where learners can abandon the algorithms altogether, and instead use memory to provide fast, efficient, automatic responses [33,34].
According to instance theory, learning can occur in a single trial, provided the learner attends to the stimulus, stores it in memory, and provides a memory-based response in an upcoming encounter with that stimulus. Of course, as more instances are stored, performance improves. The point is that extensive practice is not a prerequisite for learning [35].
The single-trial learning principle applies to both a single word and an entire text: Each can be encountered once, attended to, stored in memory, and retrieved when encountered again [36]. This concept is particularly interesting in light of the finding that episodic text representations may be formed after a single reading, and subsequently facilitate thematically related texts. Such facilitation occurred both for texts that shared with the source text a significant [37] or a small number of words (i.e., they were paraphrases that conveyed the same meaning) [38]. Single-trial facilitation lasted as long as 15 min between the first and second text [38]. This shows that a single exposure was enough to create, store, and retrieve episodic text representations from long-term memory.
If episodic text representations can provide meaning-based facilitation across thematically related texts, it would imply that learners are not limited to concrete representations. On the contrary, learners can encode whatever type of information they attend to, whether abstract or concrete [39]. Such a critical role for attention could explain why earlier research found that a second reading of a text is facilitated by the first reading whether it was scrambled or coherent. Investigators originally suggested that the facilitation resulted from word transference between texts [40]. Actually, in these studies, participants were instructed such that they attended to words rather than to the text as a whole [41,42]. When participants read for meaning, the second text was facilitated only when the first was coherent, not scrambled. This suggests that episodic text representations were responsible for the facilitation across repetition [41,43,44].
The cognitive status of SA and LA is affected by several factors, including task type (reception vs. production) and modality (auditory vs. visual). Previous investigators of diglossia have therefore called for expanding investigations beyond the word level [28]. Given its ability to accommodate text-level processing, episodic memory may provide a perspective on how SA and LA are processed at the level of the text.
Why investigate SA at the text-reading level if LA is the variety used for written communication? The answer lies in the fact that the differences between SA and LA are largely sociolinguistic. They are used for different social functions: Informal vs. formal; everyday vs. official. This means that both are subject to change as social conditions change, and change they do. For example, LA has traditionally been used for written communication, but on social media SA has become a popular choice (even if frowned upon in some circles). The topic is also important when we remember that readers understand information more easily when they assimilate it with the information they already know. SA is relevant for LA because building on available knowledge is a critical factor in becoming a fluent reader [38].
If meaning-based facilitation can occur across paraphrased text pairs [38], then reading an LA text should be facilitated by prior reading of its paraphrased counterpart. Notwithstanding the modality-dependent differences between LA and SA—LA is processed better in the visual modality, for example [27] — meaning-based facilitation is also expected to occur between an SA text and its paraphrased counterpart. Although SA texts may generate longer reading times than LA texts (because they are not practiced as much in the visual modality), it does not necessarily follow that SA texts would generate weaker facilitation effects. This is because facilitation is mediated by episodic text representations and rely on meaning, not on single-word processing.
If SA and LA are both classified as L1s [18,28,32], it is possible that facilitation could occur across type; i.e., between an SA text and its paraphrased LA counterpart, and between an LA text and its SA counterpart. Based on the single-trial learning principle and previous research [38], episodic text representations that mediate facilitation may be well established in long-term memory after a single reading and, if so, could endure long intervals between the first and second readings.
To test these hypotheses, the current study investigates facilitation across LA-LA, SA-SA, LA-SA, and SA-LA paraphrased text pairs. Of particular interest is the pattern and duration of facilitation effects.
The Volunteers (N = 60; age range 20-22 years) from the Faculty of Communication and Media at the University of Jeddah participated in the study. All were native speakers of Arabic who have been using a type of SA—a western Saudi dialect—on a daily basis for everyday communication. Throughout their entire formal education (i.e., for at least 15 years) they have also been using LA. Informed consent was obtained from all participants.
Participants read four pairs of 300-word texts; thus, eight in all: An LA source text and its target LA paraphrase (LA-LA), an SA source text and its target SA paraphrase (SA-SA), an LA source text and its target SA paraphrase (LA-SA), and an SA source text and its target LA paraphrase (SA-LA). To create the paraphrases, synonyms for as many content words as possible from the source were used in the target. Some of the substitutions, especially across mixed pairs (SA/LA, LA/SA), required slight changes in sentence structure. All paraphrases were semantically accurate: They maintained the same message.
All texts were parts of stories: LA texts were extracts from a published collection. Perhaps unexpectedly, SA texts were also taken from published collections. This rare series was intentionally written to document some stories using western Saudi SA, which, as noted, all participants use in everyday life. It should be noted that although Arabic stories are typically part of the literary genre, and written in LA, they also contain incidents and conversations for which the SA variety can be used without sounding forced or unnatural.
Participants read the texts in individual sessions that followed the protocol of Levi, et al. [38]. Texts were presented on paper. Participants were instructed to read silently, to focus on meaning, and to read as quickly as possible without backtracking because the researcher was interested in measuring reading times. Reading times to the nearest millisecond were recorded on a stopwatch by the attending researcher. The order in which the four conditions were presented was counterbalanced. Sessions lasted approximately 45 minutes each.
There were two experimental manipulations. The first was the variety-paraphrase condition. Four conditions were used: The LA variety and its LA paraphrase (LA-LA), the SA variety and its SA paraphrase (SA-SA), the LA variety and its SA paraphrase (LA-SA), and the SA variety and its LA paraphrase (SA-LA). It should be noted that to consider only the paraphrase condition, without considering the type of variety, could suggest that we are dealing with just two conditions: Within-variety (LA-LA, SA-SA) and across-variety (LA-SA, SA-LA). However, the modality-dependent differences between varieties necessitate dealing with SA-SA as different from LA-LA and SA-LA as different from LA-SA. The second manipulation was interval, which refers to the delay between reading the two texts. Half the participants read the second text immediately after the first. The other half read all four source texts, completed irrelevant activities such as word games and puzzles for 15 minutes, then read the block of target texts.
The dependent measure was reading time. An error bar chart was constructed that shows the reading times for each interval (immediate and delayed) and for the repeated measures (first and second texts) under each of the four conditions (LA-LA, SA-SA, LA-SA, and SA-LA). The chart displays the mean reading times and 95% confidence intervals (CIs, estimated by M ± t.SE). The CI is the range within which the true mean reading time would be captured 95% of the time. The error chart was interpreted using the visual method termed "inference by eye" [45] on the assumption that CIs provide "better answers to better questions" [46] and that "figures with error bars should replace p values" [47] (p. 27). If the CIs of mean values in the error bar chart do not overlap, the mean values are assumed to differ.
Repeated-measures general linear model (GLM) analysis was conducted to investigate whether the first and second texts were read at the same rate under each condition, and whether there was an effect of the interval (immediate or delayed) on first and second readings. Because repeated measures were used (i.e., two measurements of reading time per participant per condition), it was necessary to take the correlation between first and second times into account. If they were not, statistical inference would be compromised due to violation of the assumption of independent measurements associated with biased estimates of sums of squares [48].
The assumptions of repeated-measures GLM [49] were checked. The fundamental assumption that the two repeated measures must be linearly related was tested visually by regressing the reading times of the second text on the first for each condition. The inferential test statistics and p values for each effect are reported but not interpreted because statistical significance provides no useful evidence to assist the investigation.
The effect size of all within- and between-subject effects were estimated by partial eta-squared (η2P) values. Within-subjects effects refer to the repeated readings of the text, the interactions between readings and interval, and the interactions between readings and condition. Between-subjects effects refer to the fixed effects of conditions and intervals, as well as the condition-interval interactions. Effect size estimated the proportion of the variance explained by each effect. The values of η2P were interpreted by applying the criteria approved by the American Psychological Association [50]: η2P ≈ 0.04 is the smallest value to reflect a practically significant effect; η2P < 0.24 represents a small effect with limited practical significance; practically significant results are indicated by η2P > 0.25 (moderate effect) and η2P > 0.64 (strong). An effect is considered "practically significant" if it is large enough to be meaningful in real life—unlike "statistically significant," which does not measure effects in real life [51,52].
The error bar chart in Figure 1 displays the mean reading times and 95% CIs for the immediate and the delayed interval with respect to reading the first and second texts under the four conditions. Lack of overlap between CIs reflects mean differences.
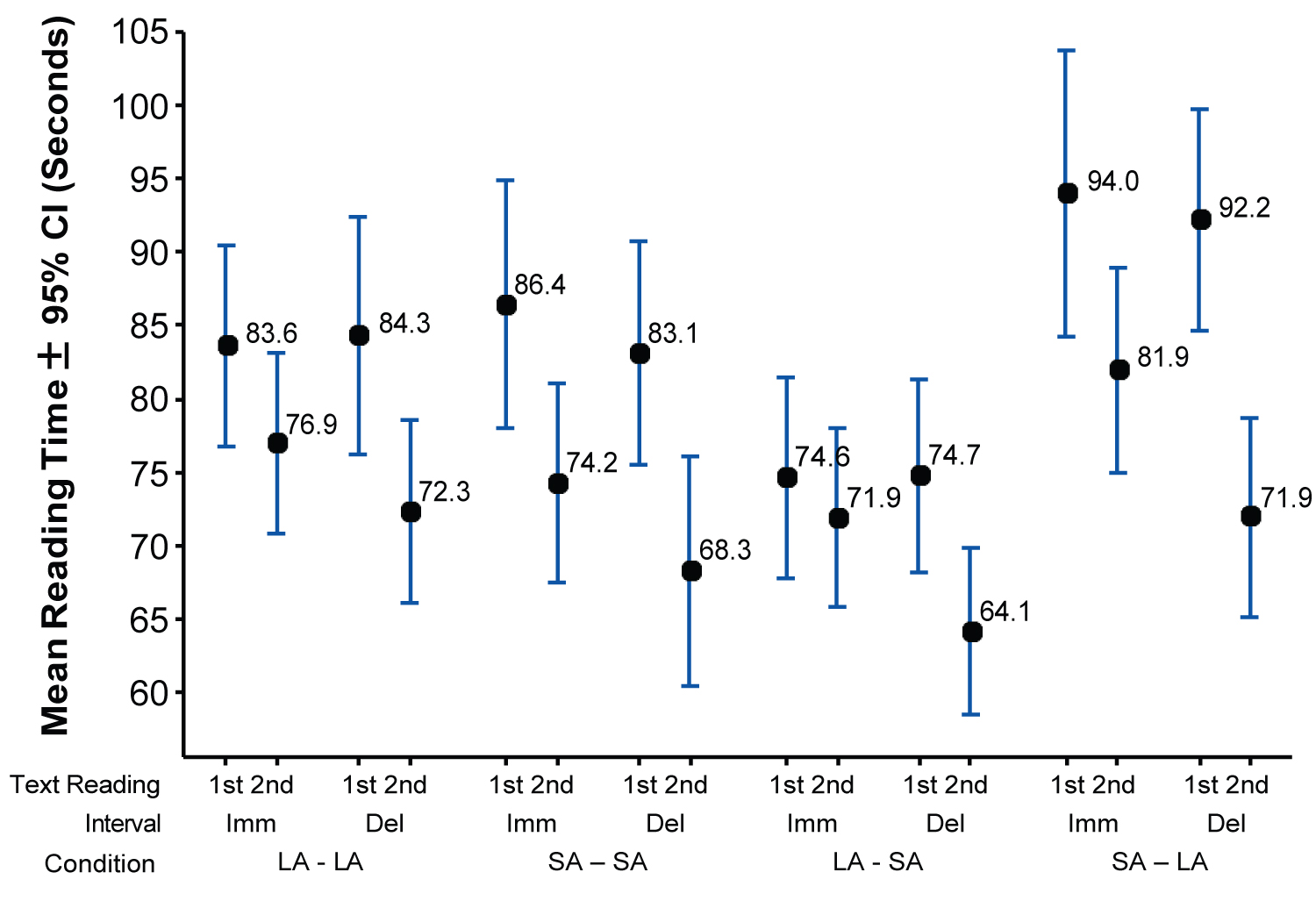 Figure 1: Note: • = Mean; ꟾ = 95% CI; Imm = Immediate; Del = Delayed.
Figure 1: Note: • = Mean; ꟾ = 95% CI; Imm = Immediate; Del = Delayed.
Comparison of mean reading times by Text reading (First vs. Second), Interval (Immediate vs. Delayed), and Condition (LA-LA, SA-SA, LA-SA, and SA-LA).
View Figure 1
Within each of the four conditions and the two intervals, the overall reading times for the first text (M = 84.1, 95% CI = 81.4, 86.8) were longer than the second (M = 72.6, 95% CI = 70.4, 75.00). The longest reading times were in the SA-LA condition for the first measure of both the immediate (M = 94.0, 95% CI = 84.2, 103.8) and delayed (M = 92.2, 95% CI = 84.7, 99.7) groups. The shortest times were for the second measure of the delayed group in the SA-SA (M = 68.3, 95%, CI = 60.4, 76.1) and LA-SA (M = 64.1, 95% CI = 58.4, 69.8) conditions.
The scatterplots fitted with regression lines in Figure 2, Figure 3, Figure 4 and Figure 5 confirm that the relationships between the repeated measures of the reading times were linear, satisfying the assumptions of repeated-measures GLM. These figures also show that the slopes of the two regression lines for the delayed and immediate groups within each condition were approximately equal. The similarities between the regression slopes reflected few or no interactions between the first and second reading times and the intervals, implying that the relationships between reading times were not strongly moderated or controlled by the intervals.
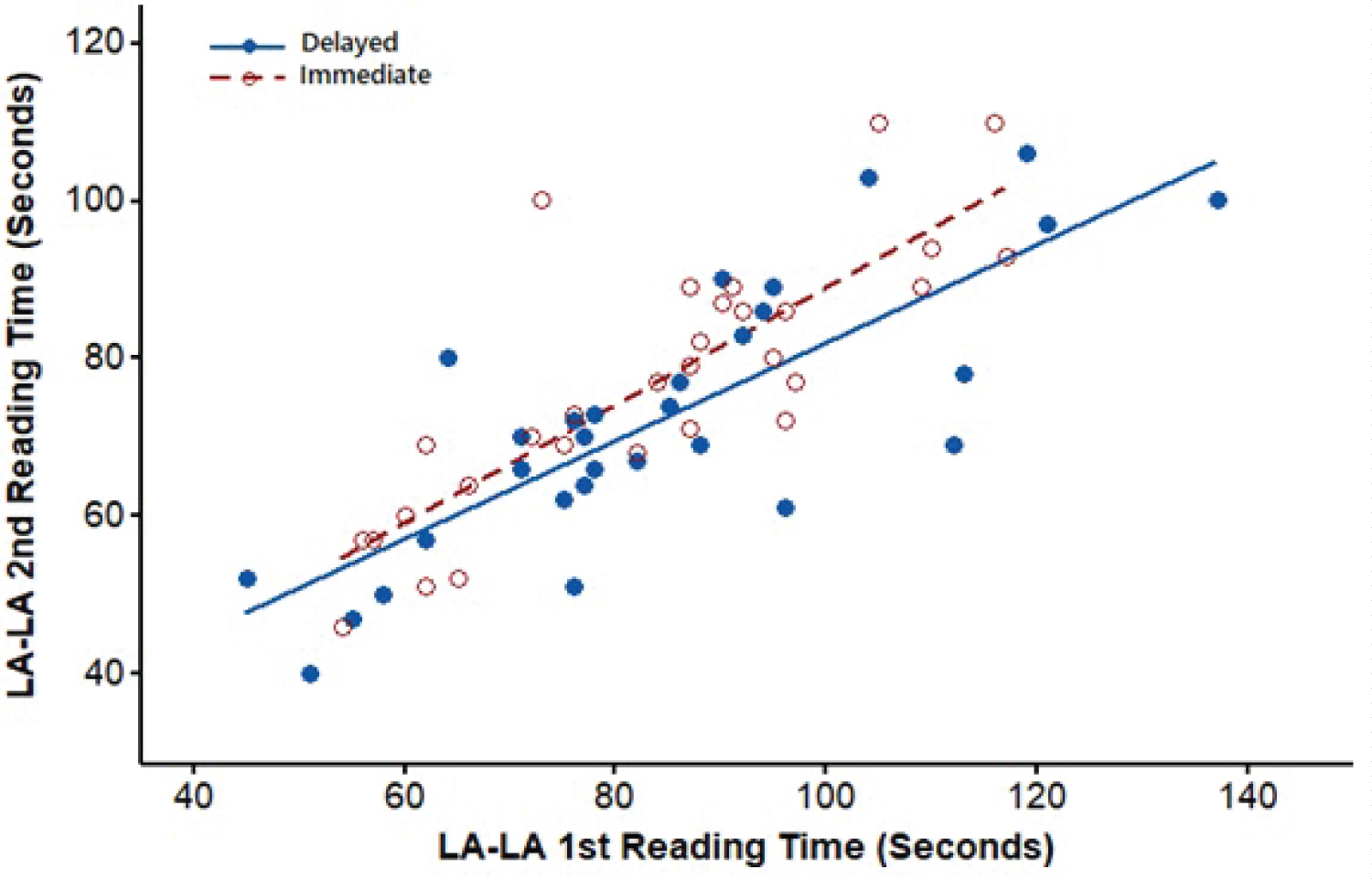 Figure 2: Regression of Second vs. First reading times under the LA-LA Condition.
View Figure 2
Figure 2: Regression of Second vs. First reading times under the LA-LA Condition.
View Figure 2
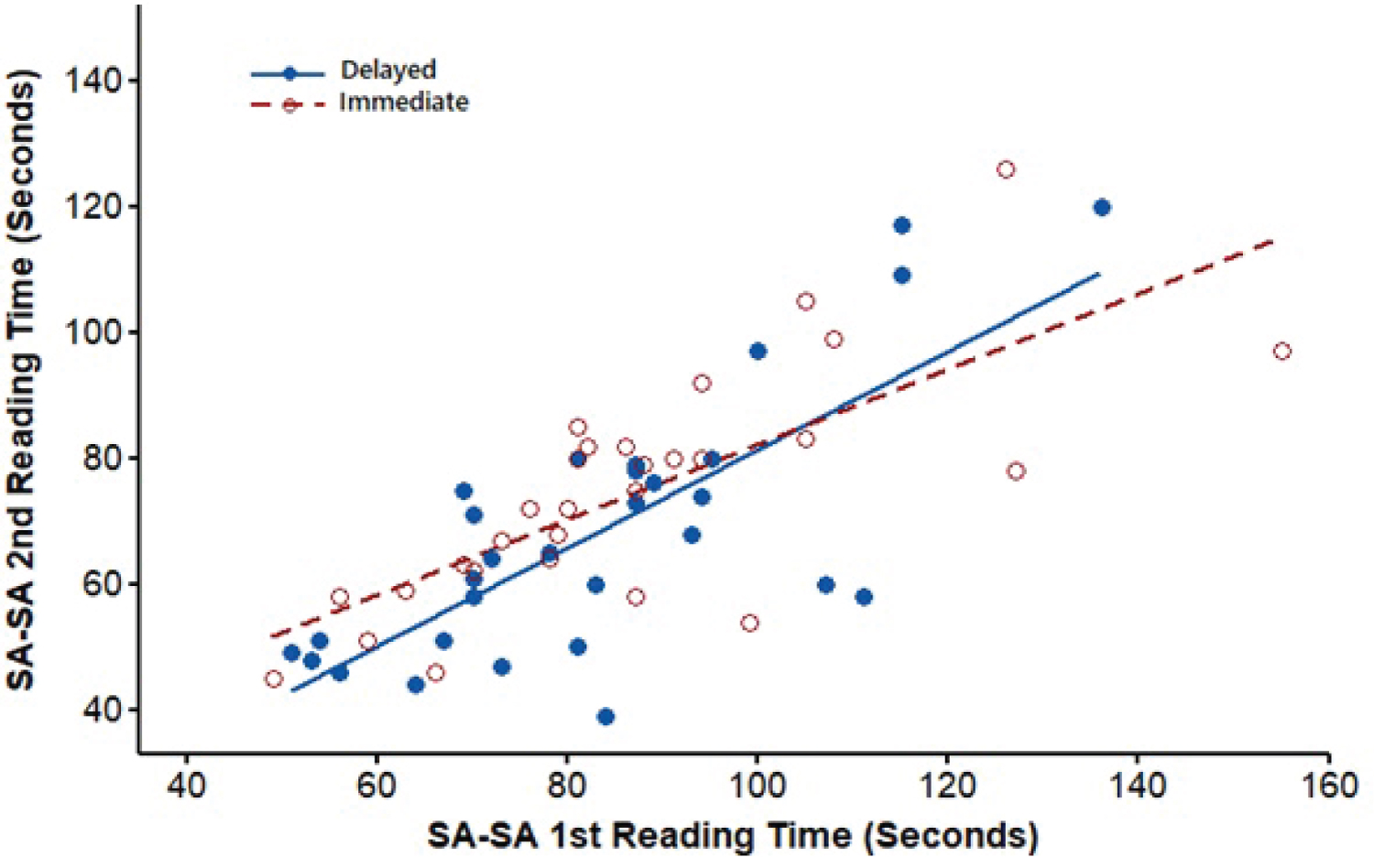 Figure 3: Regression of Second vs. First reading times under the SA-SA Condition.
View Figure 3
Figure 3: Regression of Second vs. First reading times under the SA-SA Condition.
View Figure 3
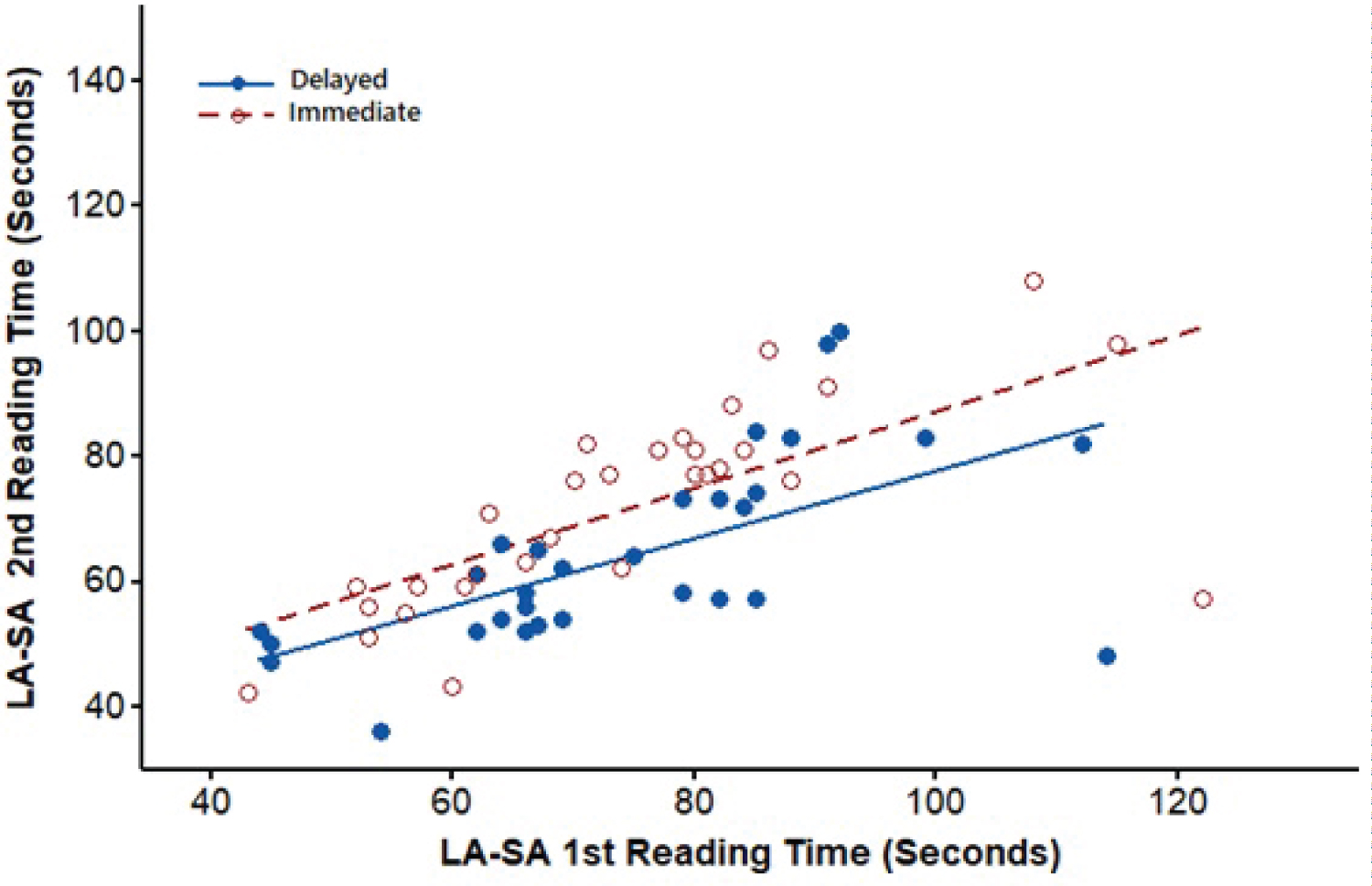 Figure 4: Regression of Second vs. First reading times under the LA-SA Condition.
View Figure 4
Figure 4: Regression of Second vs. First reading times under the LA-SA Condition.
View Figure 4
 Figure 5: Regression of Second vs. First reading times under the SA-LA Condition.
View Figure 5
Figure 5: Regression of Second vs. First reading times under the SA-LA Condition.
View Figure 5
Table 1 presents the results of the repeated-measures GLM to address whether (a) The first and second texts were read at the same rate under each condition, and (b) There was an effect of the interval between first and second texts.
Table 1: Results of repeated measures general linear model. View Table 1
The within-subjects effects involving the repeated measures indicated that the first and second texts were not read at the same rate, with a moderately strong and practically significant effect size (η2P = 0.394, p < 0.001). Irrespective of the p values, the effects on the reading times of the interaction between text readings and interval (η2P = 0.043) and between text readings and condition (η2P = 0.063) were very small, reflecting limited if any practical significance.
The between-subjects effects indicated that the very small effect of the interval on the reading times between the first and second readings (η2P = 0.013, p = 0.079) had no practical significance, confirming the interpretation of the regression lines in Figure 2, Figure 3, Figure 4 and Figure 5. Although the mean reading times varied across the four conditions, the effect size was very small, with limited practical significance (η2P = 0.071). The effect of the interaction between interval and condition was almost zero (η2P = 0.002).
For each condition the mean reading time for the first text was longer than for the second, which suggests that the reading of the first text facilitated the reading of the second. This result is consistent with previous research suggesting that episodic text representations are formed during reading and then recruited when reading thematically related texts [37,38]. The findings are also in line with our prediction that facilitation could occur between LA and SA texts and their paraphrased counterparts, whether they are from the same or the other variety. Similar to previous research in which synonyms from L1 were used to create thematically related paraphrases [38], in the present experiment, SA and LA words functioned as L1 synonyms and substituted for each other to produce meaning-based facilitation. Previously, SA and LA have been shown to behave as L1s in language production, relying on a shared lexical system [32]. The present results show that they also behave as L1s in language reception.
As shown by the similarities between the regression slopes in Figure 2, Figure 3, Figure 4 and Figure 5, the relationships between the first and second reading times were not strongly moderated or controlled by the intervals. This was further confirmed by the between-subjects effects, which indicated that the effect of the interval on the reading times had no practical significance. These findings confirm our prediction that meaning-based facilitation across all types of pairs should occur after a single reading and should endure a substantial interval between first and second reading. In other words, a single reading seems to be sufficient to create a text representation that can be stored in long-term memory and retrieved when a thematically related text is encountered. Such rapidly formed representations help exclude the possibility that it was text schemas that were transferred across texts, as schemas require multiple trials to be abstracted [38].
In line with our prediction that SA—which is not frequently practiced in the written form—will generate long reading times, the longest times were for SA texts under the SA-LA condition in the immediate and delayed groups. However, despite relatively long reading times, SA texts still provided meaning-based facilitation that survived the delay.
Reading times varied across the four conditions, but the small effect sizes confirmed that the differences due to conditions or intervals had little or no practical significance. Similarly, the effects of the interaction between conditions and interval were negligible. Taken together, these findings suggest that familiarity with the written form of the words is critical, as lack of familiarity increases the time needed to read a given text. However, familiarity is not critical for meaning-based facilitation across paraphrased texts: As the term suggests, meaning-based facilitation depends entirely on meaning, not familiarity. Thus, SA texts facilitated LA texts, and vice versa. Indeed, the shortest reading times for the second reading were for an SA text preceded by an LA text.
The "within-subjects" effect of the interaction between text readings and interval (η2P = 0.043) and between text readings and condition (η2P = 0.063) were very small, reflecting limited practical significance. Only one effect was found to be large enough to be meaningful. The moderately strong effect size indicated that the first and second texts were not read at the same rate, and this difference explained 39.4% of the variance in the reading times. The mean reading time for the first text was consistently longer than for the second text with little or no effect of interval or condition. Reading the first text facilitated the second.
This article gives a memory-based explanation of how Arabic native speakers could develop both SA and LA as an L1, and still exhibit patterns that resemble bilinguals' use of L1 and L2 while performing certain tasks. In this account, differences in using SA and LA are not the result of different cognitive or neural mechanisms, but rather the result of an item-based learning mechanism. This theoretical account guided our empirical investigation of diglossia at the level of the text. For adult Arabic native speakers, the knowledge encountered in either SA or LA facilitated subsequent reading. These findings are relevant in the current social context, as Arabic speakers are increasingly exposed to SA written content through social media, and their ability to integrate knowledge acquired in both varieties can play part in developing their reading fluency and shaping their overall reading experience.
Informed consent was obtained from all subjects involved in the study.
The author declares no conflict of interest.
This research received no external funding.